import pandas as pd
import psycopg2 as psy
from psycopg2 import Error
import numpy as np
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
import plotly.graph_objects as go
import plotly.express as px
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('white')Campeonato Mundial de la Formula 1 (1950 - 2023)
Visualización Científica
La Fórmula 1, también conocida como F1, representa la cúspide de las carreras internacionales de monoplazas de ruedas abiertas, bajo la supervisión de la Federación Internacional del Automóvil (FIA). Desde su primera temporada en 1950, el Campeonato Mundial de Pilotos, rebautizado como el Campeonato Mundial de Fórmula 1 de la FIA en 1981, ha destacado como una de las principales competiciones a nivel global. La palabra “fórmula” en su nombre alude al conjunto de reglas que guían a todos los participantes en cuanto a la construcción y funcionamiento de los vehículos.
¿Qué haremos?
En esta sección, llevaremos a cabo un análisis exploratorio centrado en la tabla drivers, que abarca los datos de los equipos que han competido en las carreras disputadas desde 1950 hasta 2023. Sin embargo, para llevar a cabo este análisis de manera integral, necesitamos consolidar información proveniente de diversas fuentes. Utilizaremos consultas para unificar los datos de la tabla drivers con aquellos de las tablas circuits (que contiene información sobre los circuitos donde se celebran las carreras de Fórmula 1), results (que proporciona los resultados de las carreras) y constructors (equipos en los que ha competido).
Es fundamental destacar que, para la tabla results nos enfocaremos exclusivamente en los pilotos que obtuvieron puntos en cada carrera.
Librerías
Para este proyecto trabajaremos con las siguientes librerías:
- Pandas
- Psycopg2
- Plotly
- Matplotlib
- Seaborn
- Scikit-learn
Pueden instalarse utilizando el siguiente comando desde la terminal: pip install pandas psycopg2 plotly..., o bien, mediante el archivo requirements.txt utilizando pip install -r requirements.txt en la terminal.
Una vez instaladas, podemos importarlas en nuestro entorno de trabajo de la siguiente manera:
Además, haremos uso de la siguiente función para evitar la repetición de código y facilitar la conexión a la base de datos:
def connection_db() -> psy.extensions.connection:
try:
conn = psy.connect(DATABASE_URL)
return conn
except (Exception, Error) as e:
print('Error while connecting to PostgreSQL', e)Es importante destacar que en esta función, obtenemos una variable de entorno que almacena los datos de conexión a la base de datos. En este caso, estamos utilizando Neon que nos permite crear un servidor de bases de datos con PostgreSQL.
Obtención de los datos
Veamos inicialmente las columnas que tenemos para cada una de las tablas mencionadas.
Tabla drivers
try:
connection = connection_db()
cursor = connection.cursor()
cursor.execute(
"""
SELECT *
FROM drivers
LIMIT 5;
"""
)
records = cursor.fetchall()
records_data = pd.DataFrame(records)
columns = []
for column in cursor.description:
columns.append(column[0])
records_data.columns = columns
display(records_data)
except (Exception, Error) as e:
print('Error while executing the query', e)
finally:
if(connection):
cursor.close()
connection.close()| driverid | driverref | number | code | forename | surname | dob | nationality | url | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | hamilton | 44.0 | HAM | Lewis | Hamilton | 1985-01-07 | British | http://en.wikipedia.org/wiki/Lewis_Hamilton |
| 1 | 2 | heidfeld | NaN | HEI | Nick | Heidfeld | 1977-05-10 | German | http://en.wikipedia.org/wiki/Nick_Heidfeld |
| 2 | 3 | rosberg | 6.0 | ROS | Nico | Rosberg | 1985-06-27 | German | http://en.wikipedia.org/wiki/Nico_Rosberg |
| 3 | 4 | alonso | 14.0 | ALO | Fernando | Alonso | 1981-07-29 | Spanish | http://en.wikipedia.org/wiki/Fernando_Alonso |
| 4 | 5 | kovalainen | NaN | KOV | Heikki | Kovalainen | 1981-10-19 | Finnish | http://en.wikipedia.org/wiki/Heikki_Kovalainen |
Tabla constructors
try:
connection = connection_db()
cursor = connection.cursor()
cursor.execute(
"""
SELECT *
FROM constructors
LIMIT 5;
"""
)
records = cursor.fetchall()
records_data = pd.DataFrame(records)
columns = []
for column in cursor.description:
columns.append(column[0])
records_data.columns = columns
display(records_data)
except (Exception, Error) as e:
print('Error while executing the query', e)
finally:
if(connection):
cursor.close()
connection.close()| constructorid | constructorref | name | nationality | url | |
|---|---|---|---|---|---|
| 0 | 1 | mclaren | McLaren | British | http://en.wikipedia.org/wiki/McLaren |
| 1 | 2 | bmw_sauber | BMW Sauber | German | http://en.wikipedia.org/wiki/BMW_Sauber |
| 2 | 3 | williams | Williams | British | http://en.wikipedia.org/wiki/Williams_Grand_Pr... |
| 3 | 4 | renault | Renault | French | http://en.wikipedia.org/wiki/Renault_in_Formul... |
| 4 | 5 | toro_rosso | Toro Rosso | Italian | http://en.wikipedia.org/wiki/Scuderia_Toro_Rosso |
Tabla circuits
try:
connection = connection_db()
cursor = connection.cursor()
cursor.execute(
"""
SELECT *
FROM circuits
LIMIT 5;
"""
)
records = cursor.fetchall()
records_data = pd.DataFrame(records)
columns = []
for column in cursor.description:
columns.append(column[0])
records_data.columns = columns
display(records_data)
except (Exception, Error) as e:
print('Error while executing the query', e)
finally:
if(connection):
cursor.close()
connection.close()| circuitid | circuitref | name | location | country | lat | lng | alt | url | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | albert_park | Albert Park Grand Prix Circuit | Melbourne | Australia | -37.8497 | 144.968 | 10 | http://en.wikipedia.org/wiki/Melbourne_Grand_P... |
| 1 | 2 | sepang | Sepang International Circuit | Kuala Lumpur | Malaysia | 2.76083 | 101.738 | 18 | http://en.wikipedia.org/wiki/Sepang_Internatio... |
| 2 | 3 | bahrain | Bahrain International Circuit | Sakhir | Bahrain | 26.0325 | 50.5106 | 7 | http://en.wikipedia.org/wiki/Bahrain_Internati... |
| 3 | 4 | catalunya | Circuit de Barcelona-Catalunya | Montmeló | Spain | 41.57 | 2.26111 | 109 | http://en.wikipedia.org/wiki/Circuit_de_Barcel... |
| 4 | 5 | istanbul | Istanbul Park | Istanbul | Turkey | 40.9517 | 29.405 | 130 | http://en.wikipedia.org/wiki/Istanbul_Park |
Tabla results
try:
connection = connection_db()
cursor = connection.cursor()
cursor.execute(
"""
SELECT *
FROM results
LIMIT 5;
"""
)
records = cursor.fetchall()
records_data = pd.DataFrame(records)
columns = []
for column in cursor.description:
columns.append(column[0])
records_data.columns = columns
display(records_data)
except (Exception, Error) as e:
print('Error while executing the query', e)
finally:
if(connection):
cursor.close()
connection.close()| resultid | raceid | driverid | constructorid | number | grid | position | positiontext | positionorder | points | laps | time | milliseconds | fastestlap | rank | fastestlaptime | fastestlapspeed | statusid | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 18 | 1 | 1 | 22 | 1 | 1 | 1 | 1 | 10 | 58 | 1:34:50.616 | 5690616 | 39 | 2 | 1:27.452 | 218.300 | 1 |
| 1 | 2 | 18 | 2 | 2 | 3 | 5 | 2 | 2 | 2 | 8 | 58 | +5.478 | 5696094 | 41 | 3 | 1:27.739 | 217.586 | 1 |
| 2 | 3 | 18 | 3 | 3 | 7 | 7 | 3 | 3 | 3 | 6 | 58 | +8.163 | 5698779 | 41 | 5 | 1:28.090 | 216.719 | 1 |
| 3 | 4 | 18 | 4 | 4 | 5 | 11 | 4 | 4 | 4 | 5 | 58 | +17.181 | 5707797 | 58 | 7 | 1:28.603 | 215.464 | 1 |
| 4 | 5 | 18 | 5 | 1 | 23 | 3 | 5 | 5 | 5 | 4 | 58 | +18.014 | 5708630 | 43 | 1 | 1:27.418 | 218.385 | 1 |
Tabla final
Con base en las columnas proporcionadas de cada tabla, podemos listar las que se utilizarán en el análisis de la siguiente manera:
- Drivers: driverid, driverref, code, dob, nationality.
- Constructors: constructorId, name.
- Circuits: name, location, country.
- Results: points, grid, laps, milliseconds, fastestlap, rank, fastestlapspeed, number, status.
Realicemos entonces la consulta a la base de datos para obtener esta tabla.
try:
connection = connection_db()
cursor = connection.cursor()
cursor.execute(
"""
SELECT
d.driverId, d.driverRef,
d.dob, d.nationality,
circuits.name AS circuit_name, circuits.location AS circuit_location, circuits.country AS circuit_country,
races.year, races.name AS race_name, races.round,
constructors.constructorId, constructors.name AS team_name,
results.number, results.grid, results.positionorder, results.points, results.laps, results.milliseconds,
results.fastestlap, results.rank, results.fastestlapspeed, results.statusid
FROM
drivers d
JOIN
results ON d.driverId = results.driverId
JOIN
races ON results.raceId = races.raceId
JOIN
circuits ON races.circuitId = circuits.circuitId
JOIN
constructors ON results.constructorId = constructors.constructorId
WHERE
results.points > 0;
"""
)
records = cursor.fetchall()
records_data = pd.DataFrame(records)
columns = []
for column in cursor.description:
columns.append(column[0])
records_data.columns = columns
display(records_data.head())
except (Exception, Error) as e:
print('Error while executing the query', e)
finally:
if(connection):
cursor.close()
connection.close()| driverid | driverref | dob | nationality | circuit_name | circuit_location | circuit_country | year | race_name | round | ... | number | grid | positionorder | points | laps | milliseconds | fastestlap | rank | fastestlapspeed | statusid | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | hamilton | 1985-01-07 | British | Albert Park Grand Prix Circuit | Melbourne | Australia | 2008 | Australian Grand Prix | 1 | ... | 22 | 1 | 1 | 10 | 58 | 5690616.0 | 39.0 | 2.0 | 218.300 | 1 |
| 1 | 2 | heidfeld | 1977-05-10 | German | Albert Park Grand Prix Circuit | Melbourne | Australia | 2008 | Australian Grand Prix | 1 | ... | 3 | 5 | 2 | 8 | 58 | 5696094.0 | 41.0 | 3.0 | 217.586 | 1 |
| 2 | 3 | rosberg | 1985-06-27 | German | Albert Park Grand Prix Circuit | Melbourne | Australia | 2008 | Australian Grand Prix | 1 | ... | 7 | 7 | 3 | 6 | 58 | 5698779.0 | 41.0 | 5.0 | 216.719 | 1 |
| 3 | 4 | alonso | 1981-07-29 | Spanish | Albert Park Grand Prix Circuit | Melbourne | Australia | 2008 | Australian Grand Prix | 1 | ... | 5 | 11 | 4 | 5 | 58 | 5707797.0 | 58.0 | 7.0 | 215.464 | 1 |
| 4 | 5 | kovalainen | 1981-10-19 | Finnish | Albert Park Grand Prix Circuit | Melbourne | Australia | 2008 | Australian Grand Prix | 1 | ... | 23 | 3 | 5 | 4 | 58 | 5708630.0 | 43.0 | 1.0 | 218.385 | 1 |
5 rows × 22 columns
Análisis exploratorio de datos
En esta sección nos sumergiremos en la comprensión de los datos disponibles, exploraremos los tipos de variables presentes, calcularemos medidas de tendencia central, llevaremos a cabo la depuración de los datos y procederemos a su visualización.
Para llevar a cabo este análisis, nos apoyaremos en el marco de trabajo establecido, APP Framework.
- Atención: Entender el conjunto de datos.
- Propósito: Establecer objetivos claros.
- Proceso: Realizar el Análisis Exploratorio de Datos (EDA) propiamente dicho.
- Beneficio: Extraer y aplicar los resultados obtenidos.
Conociendo los datos
Conocer los datos es un paso fundamental en cualquier análisis. Proporciona una comprensión inicial del problema, permite validar la calidad de los datos, seleccionar características relevantes, preparar los datos adecuadamente y generar ideas y hipótesis. En resumen, la exploración inicial de los datos sienta las bases para un análisis más profundo y asegura que los resultados sean significativos y confiables.
Tipos de datos
Para realizar un análisis exploratorio, primero debes conocer el tipo de variables con las que estamos tratando. Conocer si tenemos variables numéricas o categóricas podrían determinar el rumbo del análisis que realizaremos.
records_data.dtypesdriverid int64
driverref object
dob object
nationality object
circuit_name object
circuit_location object
circuit_country object
year int64
race_name object
round int64
constructorid int64
team_name object
number int64
grid int64
positionorder int64
points int64
laps int64
milliseconds float64
fastestlap float64
rank float64
fastestlapspeed object
statusid int64
dtype: objectObservemos que todas las variables tienen el tipo de dato correcto, excepto la columna fastestlapspeed, que toma valores numéricos pero está siendo interpretada como un dato tipo object. Por lo tanto, es necesario convertir esta columna en tipo numérico. Además, vamos a cambiar los tipos de datos de la variable driverid y constructorid a tipo object.
records_data['fastestlapspeed'] = pd.to_numeric(records_data['fastestlapspeed'])
records_data[['driverid', 'constructorid']] = records_data[['driverid', 'constructorid']].astype('object')
records_data.dtypesdriverid object
driverref object
dob object
nationality object
circuit_name object
circuit_location object
circuit_country object
year int64
race_name object
round int64
constructorid object
team_name object
number int64
grid int64
positionorder int64
points int64
laps int64
milliseconds float64
fastestlap float64
rank float64
fastestlapspeed float64
statusid int64
dtype: objectDimensiones de los registros
Determinar el tamaño de nuestros registros es fundamental, ya que nos permite comprender la magnitud de la información que estamos manejando. Esto a su vez nos ayuda a establecer posibles caminos a seguir en caso de realizar transformaciones y análisis adicionales.
records_data.shape(7830, 22)len(records_data['driverref'].unique())349Esto indica que desde el año 1950 hasta el 2023, en las más de 1000 carreras que se han llevado a cabo, han competido 73 pilotos en esta competencia. Además, teniendo casi 8000 registros significa que estamos trabajando con una cantidad considerable de datos sobre equipos constructores.
Datos faltantes
Determinar la presencia de datos faltantes es crucial, ya que puede indicar si podemos confiar en una columna para el análisis o si necesitamos tomar medidas para imputar esos valores ausentes.
records_data.isnull().sum()driverid 0
driverref 0
dob 0
nationality 0
circuit_name 0
circuit_location 0
circuit_country 0
year 0
race_name 0
round 0
constructorid 0
team_name 0
number 0
grid 0
positionorder 0
points 0
laps 0
milliseconds 1720
fastestlap 4277
rank 4266
fastestlapspeed 4277
statusid 0
dtype: int64Con los resultados obtenidos, observamos que tenemos una cantidad significativa de datos faltantes. Esta situación puede afectar los análisis futuros, dependiendo del tipo de variable que estemos considerando. Es importante determinar un método adecuado para la imputación de datos en caso de que sea necesario. Veamos el porcentaje que representa esta cantidad de datos faltantes en el total de nuestros datos.
missing_values = records_data.isnull().sum()
missing_percentage = round((missing_values / len(records_data)) * 100, 4)
missing_percentagedriverid 0.0000
driverref 0.0000
dob 0.0000
nationality 0.0000
circuit_name 0.0000
circuit_location 0.0000
circuit_country 0.0000
year 0.0000
race_name 0.0000
round 0.0000
constructorid 0.0000
team_name 0.0000
number 0.0000
grid 0.0000
positionorder 0.0000
points 0.0000
laps 0.0000
milliseconds 21.9668
fastestlap 54.6232
rank 54.4828
fastestlapspeed 54.6232
statusid 0.0000
dtype: float64Tenemos un gran porcentaje de datos faltantes en nuestras variables. Sin embargo, estos datos faltantes parecen estar concentrados en las variables relacionadas con medidas de tiempos y velocidades. Esto sugiere que estos datos podrían faltar debido a limitaciones técnicas o falta de registro en las fechas más antiguas, donde la toma de estas medidas podría no haber sido sistemática.
Para comprender mejor la distribución de estos datos faltantes, examinemos en qué fechas están ocurriendo y verifiquemos la fecha máxima y mínima en la que faltan estas observaciones.
records_data[records_data.isnull().any(axis = 1)]| driverid | driverref | dob | nationality | circuit_name | circuit_location | circuit_country | year | race_name | round | ... | number | grid | positionorder | points | laps | milliseconds | fastestlap | rank | fastestlapspeed | statusid | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 6 | nakajima | 1985-01-11 | Japanese | Albert Park Grand Prix Circuit | Melbourne | Australia | 2008 | Australian Grand Prix | 1 | ... | 8 | 13 | 6 | 3 | 57 | NaN | 50.0 | 14.0 | 212.974 | 11 |
| 6 | 7 | bourdais | 1979-02-28 | French | Albert Park Grand Prix Circuit | Melbourne | Australia | 2008 | Australian Grand Prix | 1 | ... | 14 | 17 | 7 | 2 | 55 | NaN | 22.0 | 12.0 | 213.224 | 5 |
| 7 | 8 | raikkonen | 1979-10-17 | Finnish | Albert Park Grand Prix Circuit | Melbourne | Australia | 2008 | Australian Grand Prix | 1 | ... | 1 | 15 | 8 | 1 | 53 | NaN | 20.0 | 4.0 | 217.180 | 5 |
| 67 | 8 | raikkonen | 1979-10-17 | Finnish | Silverstone Circuit | Silverstone | UK | 2008 | British Grand Prix | 9 | ... | 1 | 3 | 4 | 5 | 59 | NaN | 18.0 | 1.0 | 200.842 | 11 |
| 68 | 5 | kovalainen | 1981-10-19 | Finnish | Silverstone Circuit | Silverstone | UK | 2008 | British Grand Prix | 9 | ... | 23 | 1 | 5 | 4 | 59 | NaN | 17.0 | 5.0 | 198.728 | 11 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7688 | 846 | norris | 1999-11-13 | British | Autódromo Hermanos Rodríguez | Mexico City | Mexico | 2022 | Mexico City Grand Prix | 20 | ... | 4 | 8 | 9 | 2 | 70 | NaN | 48.0 | 17.0 | 185.779 | 11 |
| 7689 | 822 | bottas | 1989-08-28 | Finnish | Autódromo Hermanos Rodríguez | Mexico City | Mexico | 2022 | Mexico City Grand Prix | 20 | ... | 77 | 6 | 10 | 1 | 70 | NaN | 43.0 | 16.0 | 185.866 | 11 |
| 7768 | 846 | norris | 1999-11-13 | British | Circuit de Monaco | Monte-Carlo | Monaco | 2023 | Monaco Grand Prix | 6 | ... | 4 | 10 | 9 | 2 | 77 | NaN | 46.0 | 19.0 | 154.324 | 11 |
| 7769 | 857 | piastri | 2001-04-06 | Australian | Circuit de Monaco | Monte-Carlo | Monaco | 2023 | Monaco Grand Prix | 6 | ... | 81 | 11 | 10 | 1 | 77 | NaN | 47.0 | 14.0 | 154.983 | 11 |
| 7819 | 840 | stroll | 1998-10-29 | Canadian | Hungaroring | Budapest | Hungary | 2023 | Hungarian Grand Prix | 11 | ... | 18 | 14 | 10 | 1 | 69 | NaN | 54.0 | 11.0 | 189.051 | 11 |
4720 rows × 22 columns
Fecha mínima: 1950
Fecha promedio: 1984
Fecha máxima: 2023Observando estos resultados, podemos confirmar nuestra teoría. Estos registros faltantes pueden ser debidos a limitaciones técnicas en aquellos tiempos.
Exploración de los datos
En esta sección realizaremos el verdadero análisis exploratorio de nuestros datos. Abordaremos los siguientes aspectos:
Medidas de tendencia central: Calcularemos medidas como la media, la mediana y la moda para entender mejor la distribución de nuestros datos.
Limpieza de los datos: Abordaremos la limpieza de nuestros datos, incluyendo la búsqueda de datos atípicos.
Transformación: Determinaremos si es necesario aplicar alguna transformación a nuestros datos para facilitar los análisis subsiguientes.
Visualización: Utilizaremos herramientas gráficas para explorar el comportamiento de nuestros datos y extraer patrones o tendencias.
Esta fase nos permitirá comprender mejor la naturaleza de nuestros datos y prepararlos adecuadamente para análisis más avanzados.
Medidas de tendencia central
records_data.describe()| year | round | number | grid | positionorder | points | laps | milliseconds | fastestlap | rank | fastestlapspeed | statusid | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 7830.000000 | 7830.000000 | 7830.000000 | 7830.000000 | 7830.000000 | 7830.000000 | 7830.000000 | 6.110000e+03 | 3553.000000 | 3564.000000 | 3553.000000 | 7830.000000 |
| mean | 1995.771520 | 8.717880 | 14.807791 | 7.120817 | 4.314815 | 6.352618 | 63.614304 | 6.183581e+06 | 46.603152 | 6.680415 | 206.006290 | 3.538697 |
| std | 20.267524 | 5.186542 | 15.616540 | 5.022058 | 2.505760 | 5.574510 | 18.795303 | 1.514364e+06 | 14.355980 | 4.232408 | 20.582848 | 6.342502 |
| min | 1950.000000 | 1.000000 | 0.000000 | 0.000000 | 1.000000 | 1.000000 | 1.000000 | 2.070710e+05 | 2.000000 | 0.000000 | 147.980000 | 1.000000 |
| 25% | 1980.000000 | 4.000000 | 5.000000 | 3.000000 | 2.000000 | 2.000000 | 54.000000 | 5.405438e+06 | 39.000000 | 3.000000 | 195.557000 | 1.000000 |
| 50% | 2000.000000 | 8.000000 | 10.000000 | 6.000000 | 4.000000 | 4.000000 | 62.000000 | 5.802887e+06 | 48.000000 | 6.000000 | 206.603000 | 1.000000 |
| 75% | 2013.000000 | 13.000000 | 20.000000 | 10.000000 | 6.000000 | 9.000000 | 71.000000 | 6.415483e+06 | 56.000000 | 10.000000 | 219.005000 | 1.000000 |
| max | 2023.000000 | 22.000000 | 117.000000 | 33.000000 | 33.000000 | 50.000000 | 200.000000 | 1.472659e+07 | 85.000000 | 20.000000 | 257.320000 | 131.000000 |
Estos resultados nos pueden permitir concluir lo siguiente:
Ronda: El número promedio de rondas por temporada es de aproximadamente 8.72, con una desviación estándar de aproximadamente 5.19. Esto sugiere que hay una variabilidad en la cantidad de rondas que se llevan a cabo en diferentes temporadas de Fórmula 1.
Número de participantes, posición de salida y orden de llegada: Se observa una variabilidad significativa en el número de participantes por carrera, con un promedio de aproximadamente 14.81. Esta variabilidad puede atribuirse a factores como las regulaciones de la Fórmula 1 que pueden influir en la participación de equipos y pilotos en diferentes eventos. La posición en la parrilla de salida, con un promedio de alrededor de 7.12, refleja las diferencias en el rendimiento de los pilotos durante la clasificación, que puede estar influenciada por la aerodinámica del automóvil, la configuración del circuito y las habilidades individuales de los pilotos. A pesar de la variabilidad en la posición inicial, el orden promedio de llegada es de aproximadamente 4.31, lo que sugiere que, en promedio, los pilotos logran avanzar durante la carrera, ya sea mediante adelantamientos en pista o a través de estrategias de pit stop.
Número de vueltas y tiempo de carrera: La cantidad promedio de vueltas completadas por carrera es de aproximadamente 63.61. Esta variabilidad puede ser atribuida a factores como la longitud y complejidad del circuito, así como la presencia de incidentes en pista que pueden afectar la duración de la carrera. El tiempo medio de carrera, aproximadamente 103 minutos, refleja la suma del tiempo requerido para completar todas las vueltas, así como los períodos de posibles intervenciones, como banderas amarillas o detenciones en boxes. La consistencia en la duración de la carrera sugiere una cierta estandarización en el formato de los eventos de la Fórmula 1, aunque la variabilidad aún puede ocurrir debido a diferentes condiciones de pista y estrategias de carrera.
Mejor vuelta, velocidad más rápida y puntos: La vuelta más rápida realizada por el ganador, con un promedio de alrededor de 206.01 km/h y una desviación estándar de aproximadamente 20.58 km/h, refleja el rendimiento máximo alcanzado por los pilotos durante la carrera. Esta velocidad puede variar según las condiciones del circuito y la estrategia de los equipos. En cuanto a los puntos obtenidos, con un promedio de aproximadamente 6.35, reflejan la efectividad de los pilotos y equipos para acumular puntos en cada evento. Esta puntuación puede influir en el desarrollo del campeonato y reflejar la consistencia y el rendimiento a lo largo de la temporada.
Limpieza de los datos
La limpieza de datos es una etapa crucial en cualquier análisis, por lo que en este apartado trataremos los datos faltantes y observaremos si existen datos atípicos en nuestras variables.
Datos faltantes
Existen diversas estrategias para abordar este problema. Usualmente, en este tipo de análisis se recurre a la imputación de valores faltantes utilizando la media, moda o mediana, o llenando los datos con los valores anteriores o siguientes. Sin embargo, estas técnicas pueden no ser óptimas para conjuntos de datos extensos o con características específicas.
En nuestro caso, una estrategia efectiva sería utilizar la imputación de datos faltantes basada en puntos similares en los datos mediante el algoritmo KNN (K-Nearest Neighbors) y Random Forest Classification. Este método considera las características de observaciones similares para estimar los valores faltantes de manera más precisa y realista, lo que resulta especialmente útil en conjuntos de datos complejos como el nuestro.
Inicialmente, creemos un DataFrame temporal donde estarán los mismos datos de records_data pero sin las columnas correspondientes a tipo object.
temp_df = records_data.select_dtypes(exclude=['object'])
imputer = IterativeImputer(min_value=0, max_iter=30, imputation_order='roman', random_state=1)
imputed_data = imputer.fit_transform(temp_df)
temp_df_imputed = pd.DataFrame(imputed_data, columns=temp_df.columns)
temp_df_imputed.isnull().sum()year 0
round 0
number 0
grid 0
positionorder 0
points 0
laps 0
milliseconds 0
fastestlap 0
rank 0
fastestlapspeed 0
statusid 0
dtype: int64Bien, ya no tenemos datos faltantes. Ahora, verifiquemos si los resultados obtenidos en las medidas de tendencia central del DataFrame original cambiaron significativamente.
temp_df_imputed.describe()| year | round | number | grid | positionorder | points | laps | milliseconds | fastestlap | rank | fastestlapspeed | statusid | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 7830.000000 | 7830.000000 | 7830.000000 | 7830.000000 | 7830.000000 | 7830.000000 | 7830.000000 | 7.830000e+03 | 7830.000000 | 7830.000000 | 7830.000000 | 7830.000000 |
| mean | 1995.771520 | 8.717880 | 14.807791 | 7.120817 | 4.314815 | 6.352618 | 63.614304 | 6.357840e+06 | 37.583611 | 5.902056 | 191.230541 | 3.538697 |
| std | 20.267524 | 5.186542 | 15.616540 | 5.022058 | 2.505760 | 5.574510 | 18.795303 | 1.503172e+06 | 17.275427 | 3.355313 | 33.140535 | 6.342502 |
| min | 1950.000000 | 1.000000 | 0.000000 | 0.000000 | 1.000000 | 1.000000 | 1.000000 | 2.070710e+05 | 0.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 1980.000000 | 4.000000 | 5.000000 | 3.000000 | 2.000000 | 2.000000 | 54.000000 | 5.484704e+06 | 27.278717 | 3.307868 | 176.963262 | 1.000000 |
| 50% | 2000.000000 | 8.000000 | 10.000000 | 6.000000 | 4.000000 | 4.000000 | 62.000000 | 5.952724e+06 | 37.110519 | 5.285219 | 196.594000 | 1.000000 |
| 75% | 2013.000000 | 13.000000 | 20.000000 | 10.000000 | 6.000000 | 9.000000 | 71.000000 | 6.815400e+06 | 48.000000 | 7.720035 | 210.953515 | 1.000000 |
| max | 2023.000000 | 22.000000 | 117.000000 | 33.000000 | 33.000000 | 50.000000 | 200.000000 | 1.520664e+07 | 135.030294 | 31.667058 | 325.915900 | 131.000000 |
Comparando los resultados de las medidas de tendencia central antes y después de la imputación de datos con el algoritmo KNN, observamos algunas diferencias significativas en ciertas variables:
Número de vueltas y tiempo de carrera: Ambos conjuntos de datos muestran una distribución similar en el número de vueltas por carrera, con una media y desviación estándar comparables. Sin embargo, se observan diferencias mínimas en el tiempo medio de carrera entre los dos conjuntos de datos, lo que indica que no se ha visto afectada la dispersión luego de la imputación.
Mejor vuelta y velocidad más rápida: Las estadísticas de la mejor vuelta y la velocidad más rápida son comparables entre los dos conjuntos de datos, lo que sugiere una consistencia en la imputación de los datos faltantes.
Ahora que hemos realizado la imputación de datos, pasemos estos datos a nuestro dataframe original.
records_data[temp_df.columns] = temp_df_imputed
records_data.isnull().sum()driverid 0
driverref 0
dob 0
nationality 0
circuit_name 0
circuit_location 0
circuit_country 0
year 0
race_name 0
round 0
constructorid 0
team_name 0
number 0
grid 0
positionorder 0
points 0
laps 0
milliseconds 0
fastestlap 0
rank 0
fastestlapspeed 0
statusid 0
dtype: int64Datos atípicos
Veamos ahora si existen datos atípicos en nuestro registro. En este caso, utilizaremos el rango intercuartílico (IQR) para identificar los valores atípicos. Si un valor cae por debajo de Q1 - 1.5 * IQR o por encima de Q3 + 1.5 * IQR, se considera un valor atípico.
numeric_columns = temp_df.columns
for col in numeric_columns:
q1 = records_data[col].quantile(0.25)
q3 = records_data[col].quantile(0.75)
iqr = q3 - q1
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
outliers = records_data[(records_data[col] < lower_bound) | (records_data[col] > upper_bound)]
n_outliers = len(outliers)
print(f'#Outliers in {col} are {n_outliers} and represent a {round(n_outliers/len(records_data) * 100, 4)}% of total records')#Outliers in year are 0 and represent a 0.0% of total records
#Outliers in round are 0 and represent a 0.0% of total records
#Outliers in number are 544 and represent a 6.9476% of total records
#Outliers in grid are 105 and represent a 1.341% of total records
#Outliers in positionorder are 12 and represent a 0.1533% of total records
#Outliers in points are 274 and represent a 3.4994% of total records
#Outliers in laps are 412 and represent a 5.2618% of total records
#Outliers in milliseconds are 542 and represent a 6.9221% of total records
#Outliers in fastestlap are 63 and represent a 0.8046% of total records
#Outliers in rank are 196 and represent a 2.5032% of total records
#Outliers in fastestlapspeed are 331 and represent a 4.2273% of total records
#Outliers in statusid are 1719 and represent a 21.954% of total recordsComo podemos observar, respecto a los más de 7000 registros que tiene la tabla, hay una pequeña cantidad significativa de datos atípicos en nuestras variables. Veamos gráficamente qué es lo que está ocurriendo con ellos. Y, aunque statusid tiene una gran cantidad de datos atípicos, esta es una variable categórica y que solo describe el estado de finalización de una carrera.
Realizaremos un gráfico de caja y bigotes e histogramas para ver el comportamiento y la distribución de nuestros datos.
plt.figure(figsize=(9,12))
i = 1
for col in numeric_columns:
plt.subplot(5,3,i)
plt.boxplot(records_data[col],whis=1.5)
plt.title(col)
i += 1
plt.show()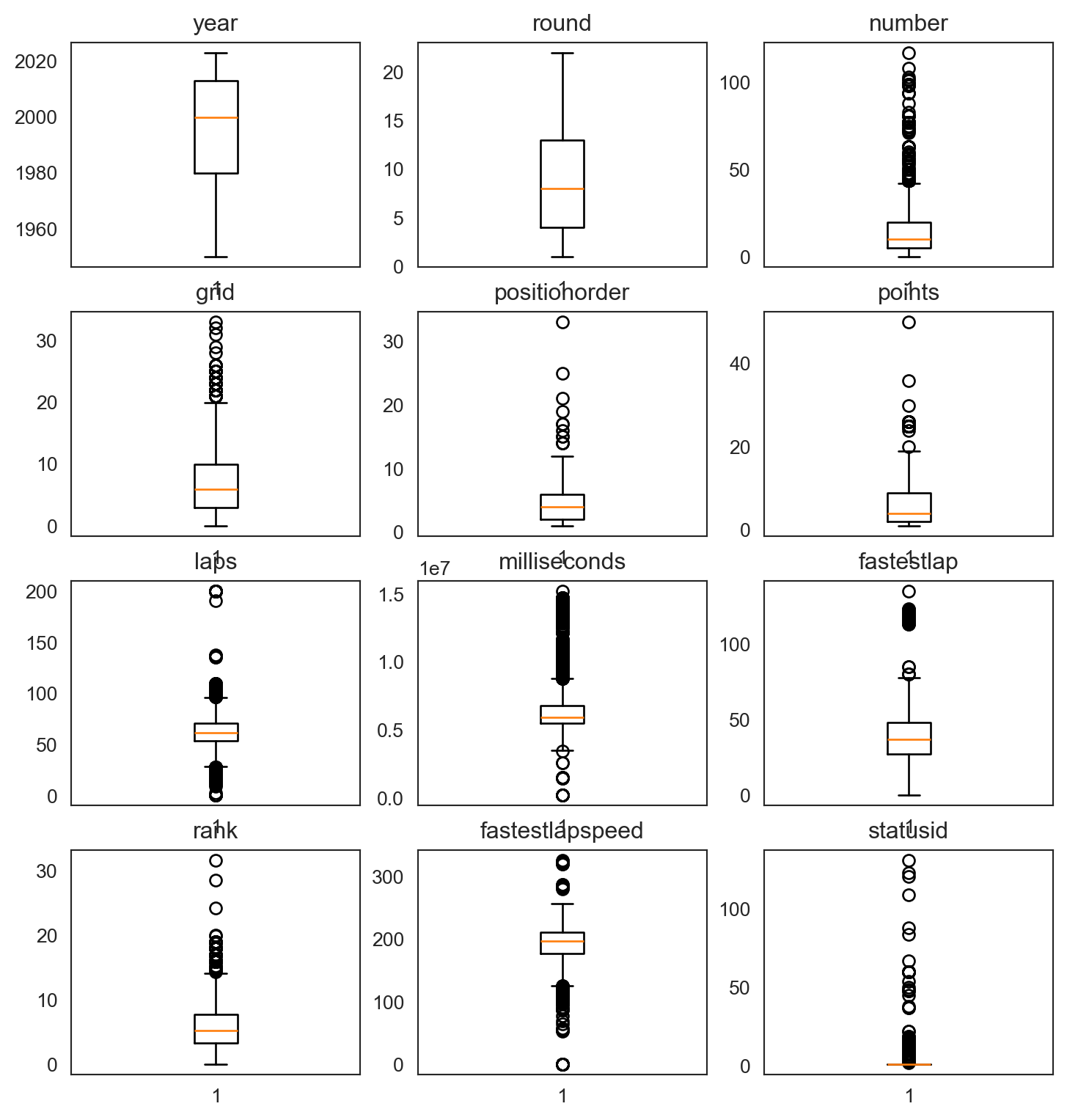
plt.figure(figsize=(8,12))
i = 1
for col in numeric_columns:
plt.subplot(5, 3, i)
sns.histplot(records_data[col], kde=True)
plt.title(col)
i += 1
plt.tight_layout()
plt.show()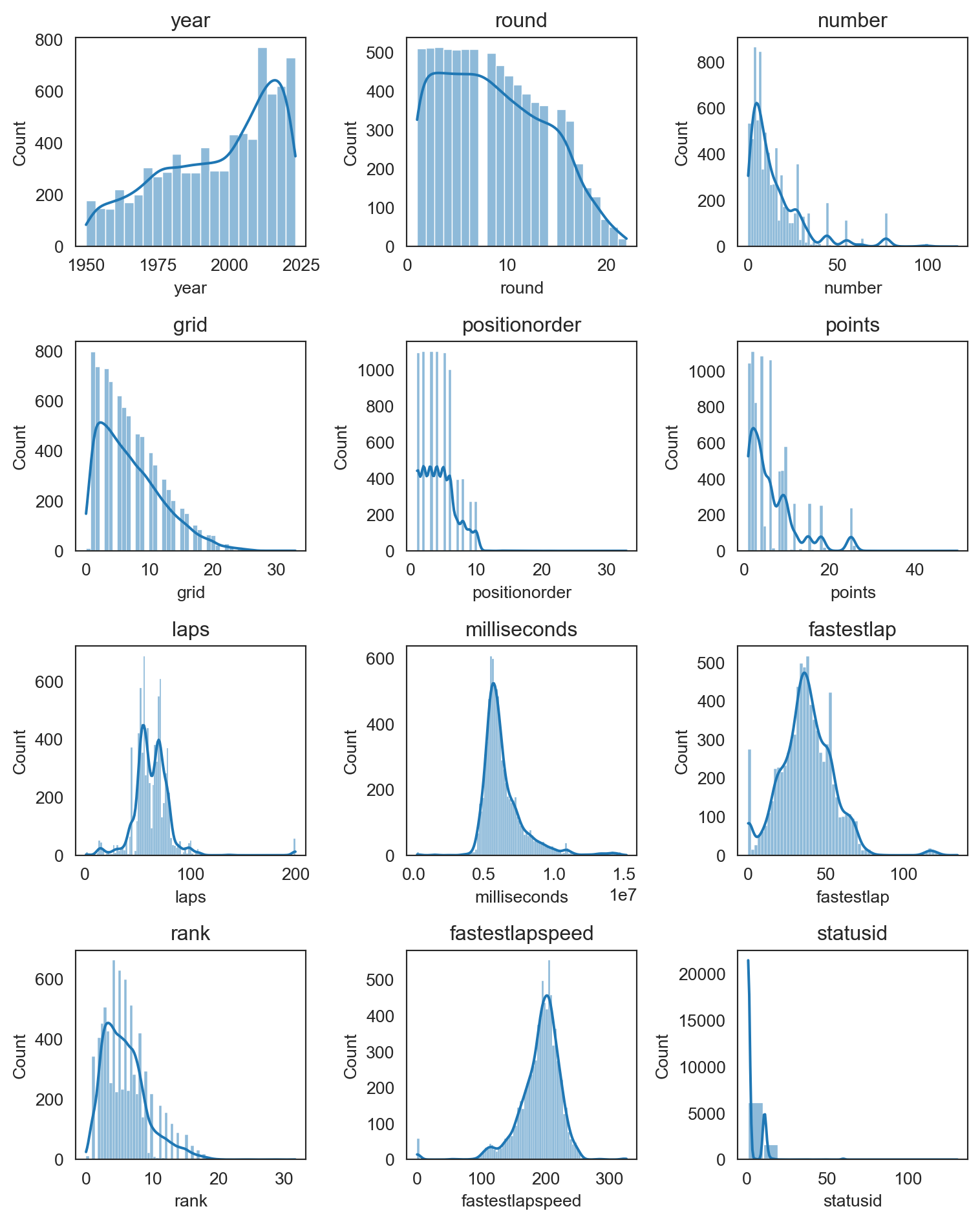
Dada la naturaleza de las variables, en algunos casos como round, positionorder, grid, points, entre otros que son datos numéricos discretos y representan una categoría específica, es normal que existan datos atípicos. Por otro lado, para las otras variables en nuestra base de datos, estos datos atípicos no están afectando mucho la distribución de cada una de ellas, por lo tanto, no realizaremos cambios en ellas.
Visualización
La visualización es uno de los puntos más importantes a la hora de realizar una exploración de los datos. Con ella, no solo podemos encontrar las relaciones que existen entre nuestras variables, sino que también podemos representar gráficamente las informaciones más relevantes de los datos.
Comencemos visualizando los gráficos de correlación y dispersión entre las variables para comprender mejor sus relaciones y encontrar posibles patrones.
Gráfico de correlación
corr = records_data[numeric_columns].corr()
mask = np.triu(np.ones_like(corr, dtype=bool))
sns.heatmap(corr, annot=True, cmap='PRGn', square=True, center=0, mask=mask)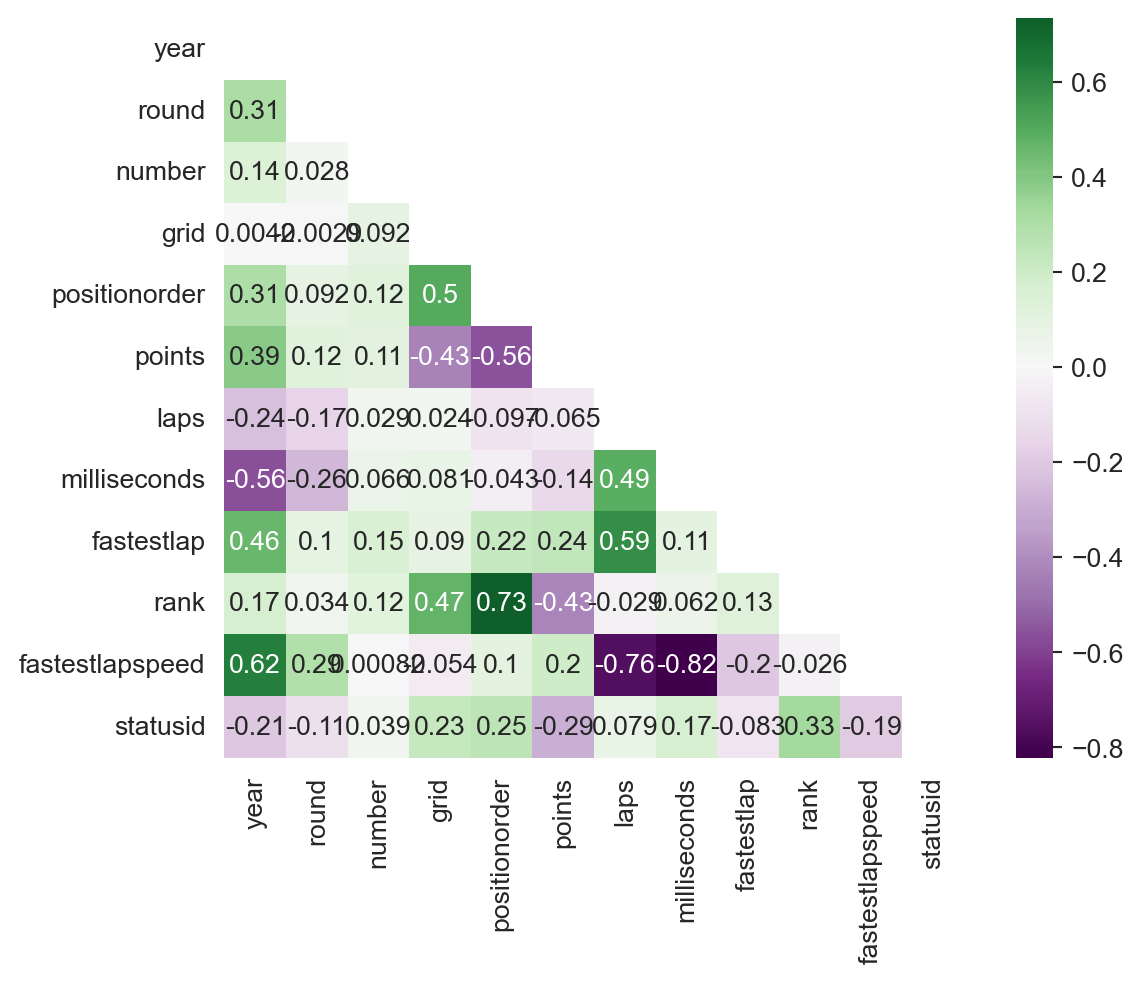
Como podemos observar, las variables con una alta correlación (>0.5 o <-0.5) son aquellas que están relacionadas entre sí, como laps, fastestlapspeed, fastest_lap, positionorder, year, fastest_pip_stop entre otras. Por lo tanto, esto no debería ser un problema y podemos proseguir con la exploración de los datos.
Gráfico de dispersión
plt.figure(figsize=(8, 12))
sns.pairplot(records_data[numeric_columns])
plt.show()<Figure size 768x1152 with 0 Axes>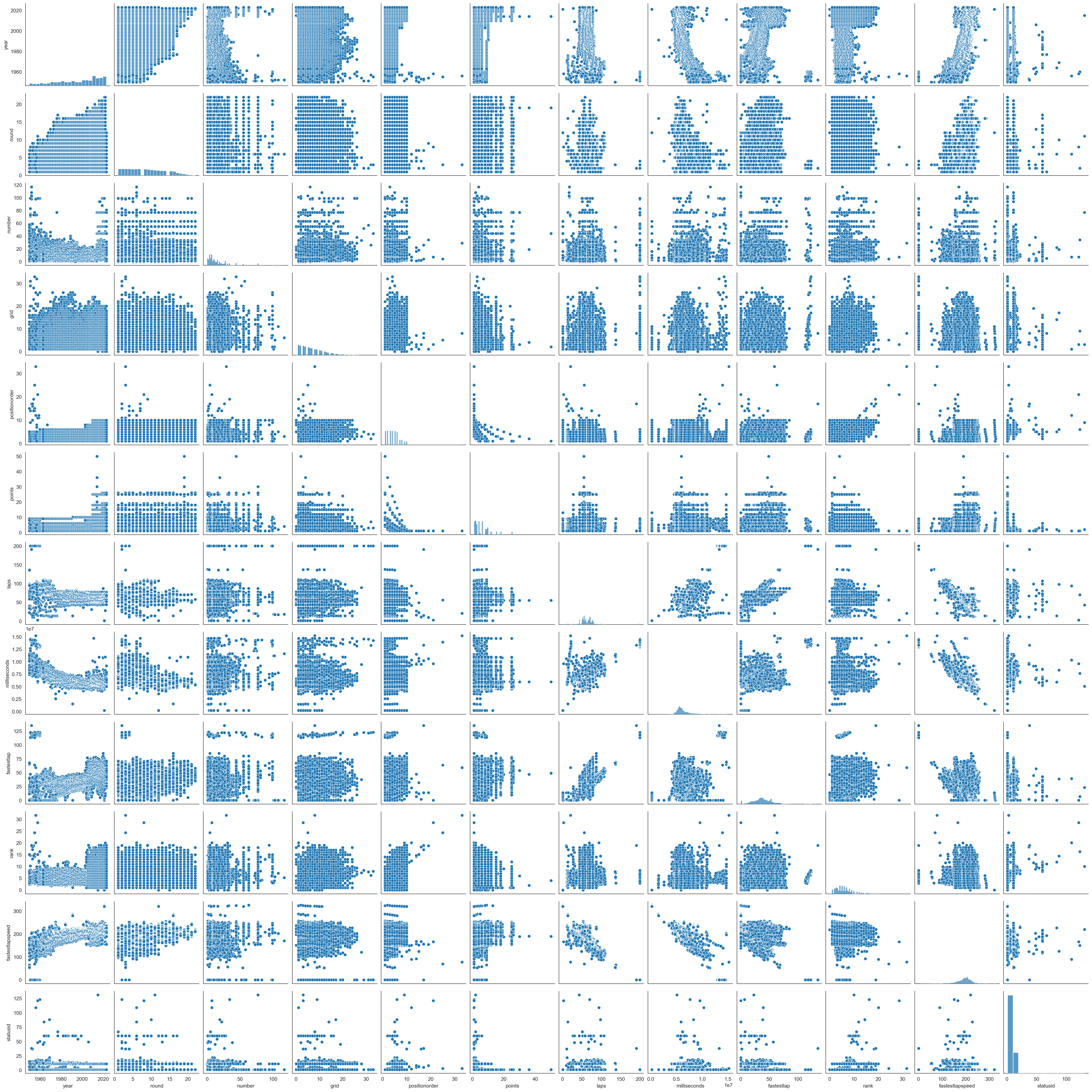
De este gráfico podemos notar que a medida que pasan los años, los equipos han ha evolucionado progresivamente en términos de velocidades y tiempos de carreras obtenidos. La velocidad y duración en boxes han aumentado, lo que indica una mejora en los automóviles y las técnicas de revisión de ellos. Sin embargo, estos cambios en las velocidades y tiempos también se han vuelto más dispersos a lo largo de los años, lo que implica que ha habido una gran diferencia entre los equipos constructores. Además, también podemos observar algunas relaciones proporcionales en nuestras variables, como aquellas relacionadas nuevamente con las velocidades y tiempos.
Distribución de carreras por piloto
driver_stats = records_data.groupby('driverref').size().reset_index(name='total_races')
driver_stats = driver_stats.sort_values(by='total_races', ascending=False)
driver_stats = driver_stats.rename(columns={'driverref': 'driver_name'})
top_constructors = driver_stats.head(5)
plt.figure(figsize=(8, 7))
sns.histplot(driver_stats['total_races'], kde=False, bins=30, color='skyblue', edgecolor='black')
plt.title('Distribución del número total de carreras por piloto')
plt.xlabel('Número Total de Carreras')
plt.ylabel('Frecuencia')
text = '\n'.join([f"{i+1}. {row['driver_name']}: {row['total_races']} carreras" for i, (index, row) in enumerate(top_constructors.iterrows(), start=0)])
plt.text(max(top_constructors['total_races']) * 1.02, plt.ylim()[1] * 0.9, text, ha='right', va='top', fontsize=10)
plt.tight_layout()
plt.show()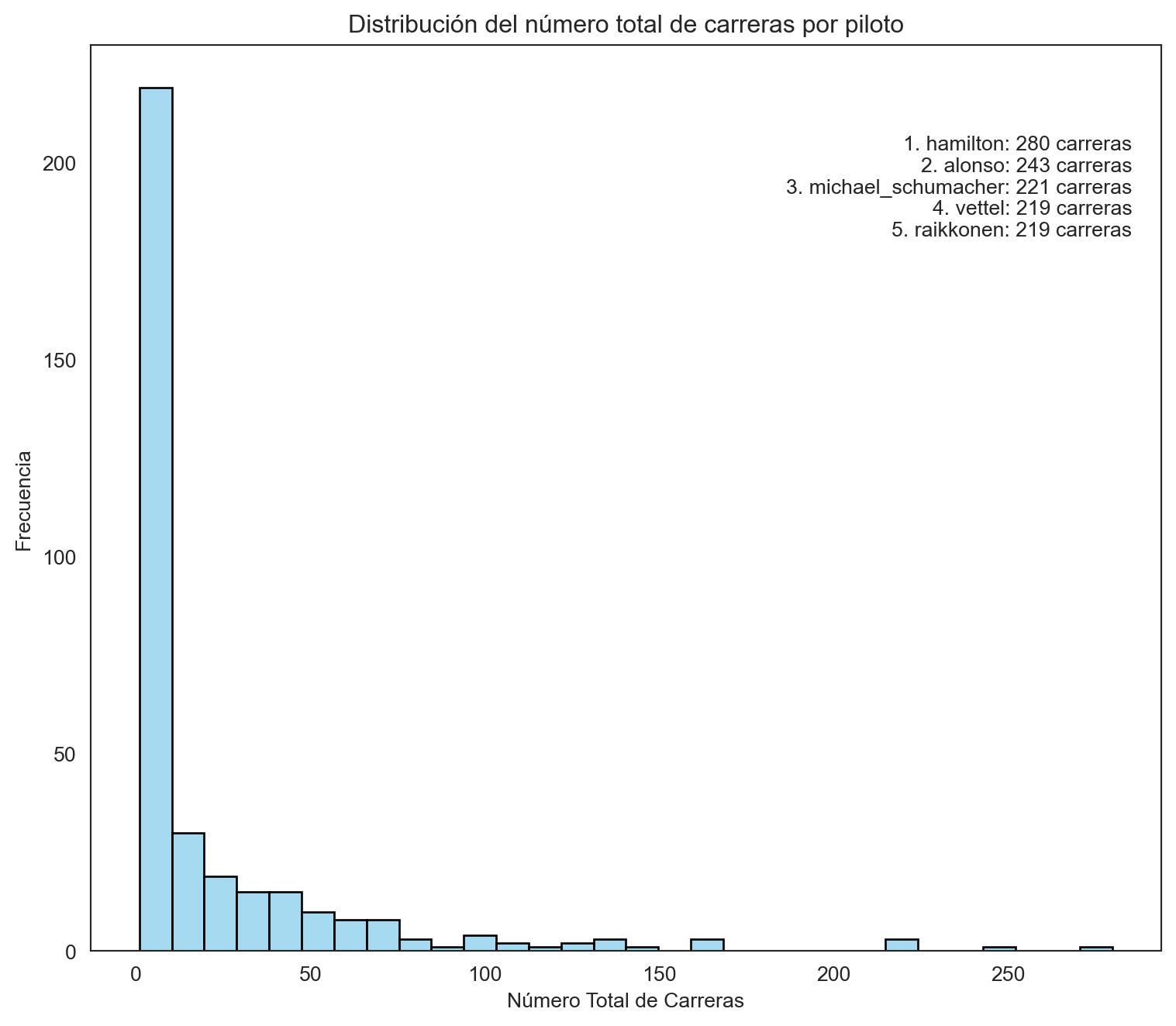
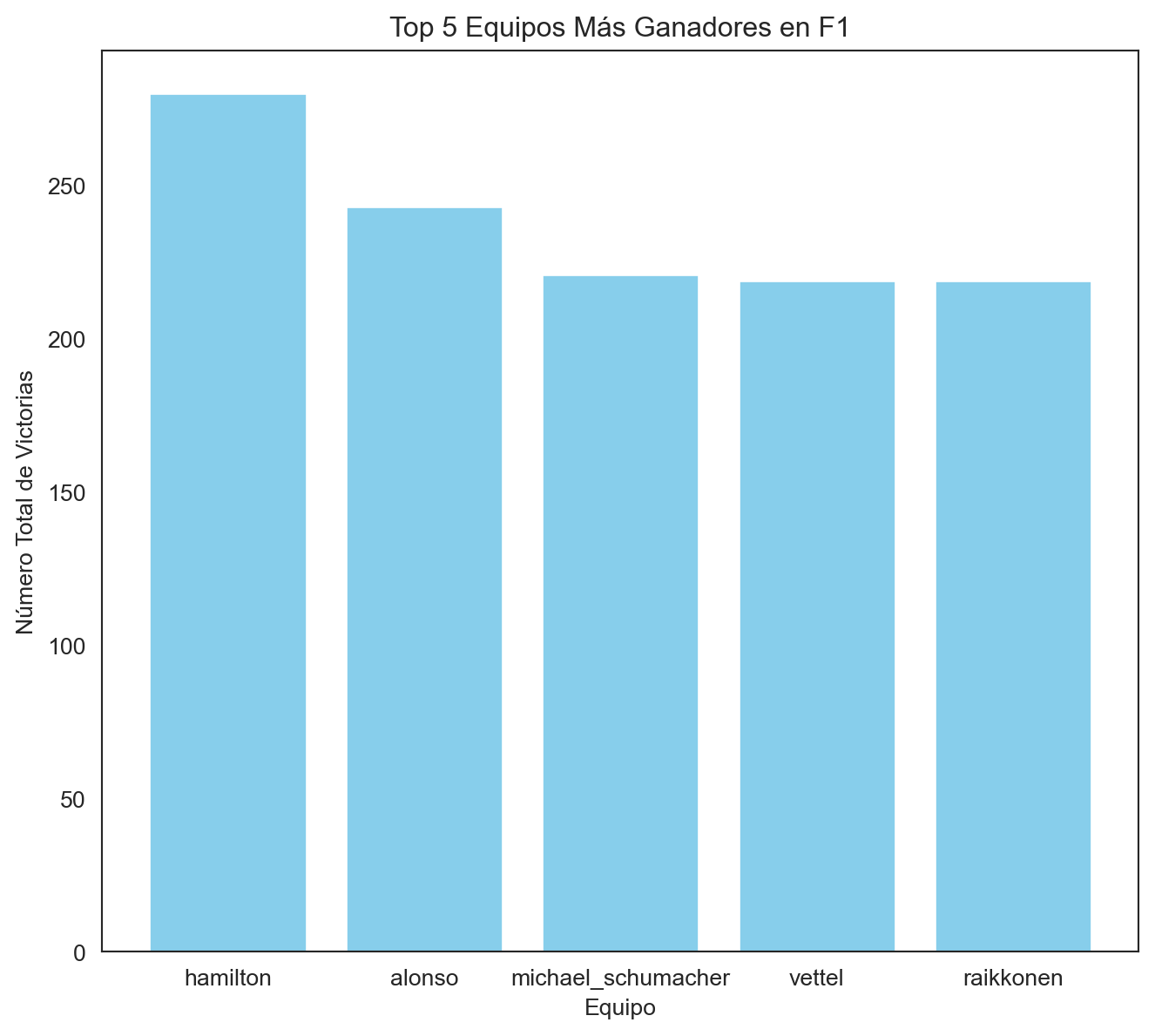
Top 5 pilotos más ganadores
driver_stats = records_data[records_data['positionorder'] == 1]
driver_stats = records_data.groupby('driverref').size().reset_index(name='total_wins')
driver_stats = driver_stats.sort_values(by='total_wins', ascending=False)
driver_stats = driver_stats.rename(columns={'driverref': 'driver_name'})
top_constructors = driver_stats.head(5)
plt.figure(figsize=(8, 7))
plt.bar(top_constructors['driver_name'], top_constructors['total_wins'], color='skyblue')
plt.title('Top 5 Equipos Más Ganadores en F1')
plt.xlabel('Equipo')
plt.ylabel('Número Total de Victorias')
plt.xticks()
plt.show()